Globetrotter: Connecting Languages by Connecting Images
2 UC Berkeley
Download

Machine translation between many languages at once is highly challenging, since training with ground truth requires supervision between all language pairs, which is difficult to obtain. Our key insight is that, while languages may vary drastically, the underlying visual appearance of the world remains consistent. We introduce a method that uses visual observations to bridge the gap between languages, rather than relying on parallel corpora or topological properties of the representations. We train a model that aligns segments of text from different languages if and only if the images associated with them are similar and each image in turn is well-aligned with its textual description. We train our model from scratch on a new dataset of text in over fifty languages with accompanying images. Experiments show that our method outperforms previous work on unsupervised word and sentence translation using retrieval.
Paper

@article{globetrotter,
title={Globetrotter: Connecting Languages by Connecting Images},
author={Sur\'is, D\'idac and Epstein, Dave and Vondrick, Carl},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
Approach
Our model learns an aligned embedding space for language translation by leveraging a transitive relation through vision. Cross-sentence similarity βij is estimated by the path through an image collection. Our approach learns this path by using both cross-modal (text-image) and visual similarity metrics. We do not use any paired data across languages.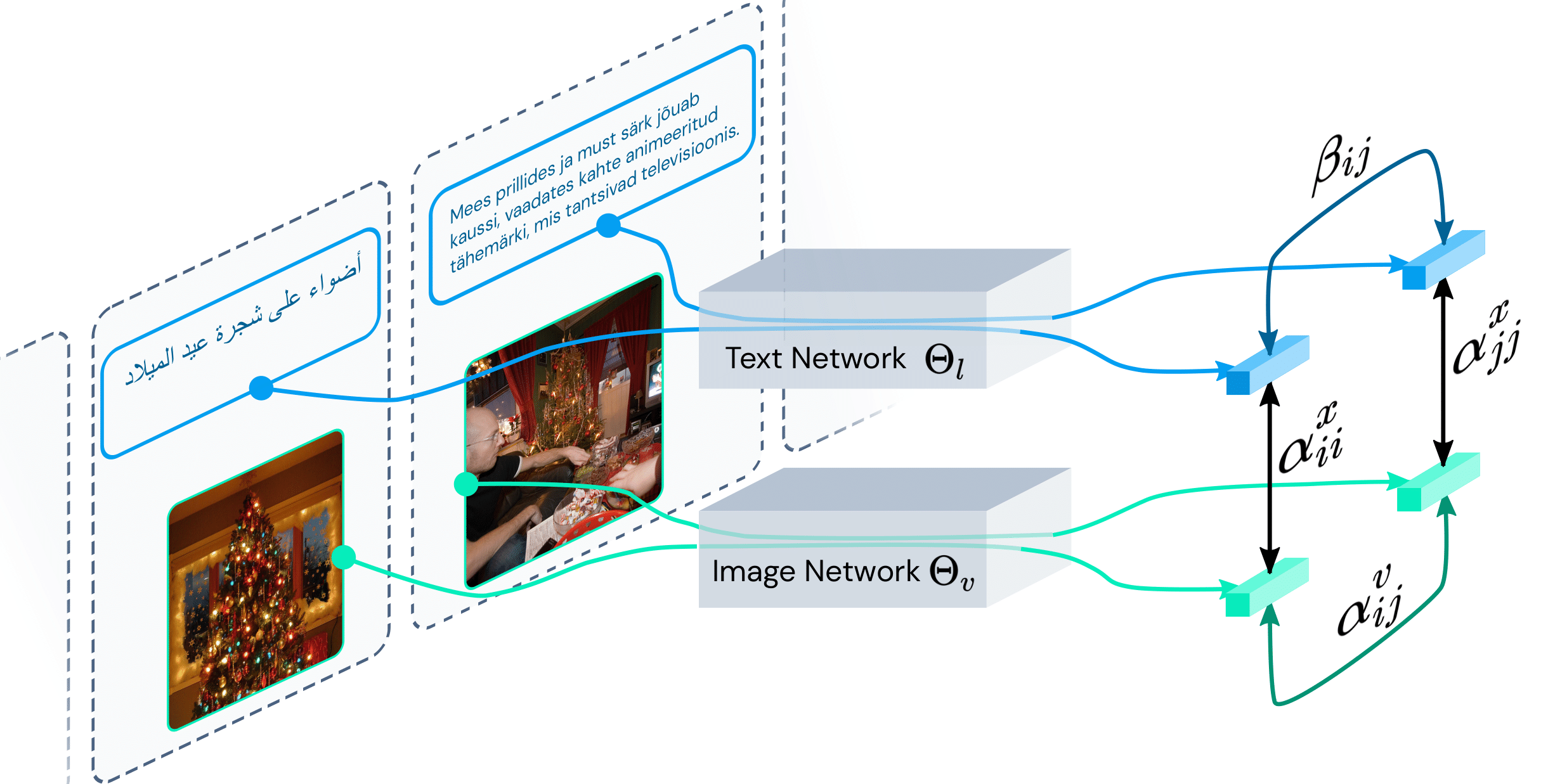
Code, data and pretrained models
For this project we collected a dataset of image descriptions for 52 different languages. The training set contains descriptions of images that do not overlap across languages, and the testing set contains descriptions for the same images for all the languages. We release our code, dataset and pretrained models. Please check our Github project for more information.Acknowledgements
This research is based on work partially supported by the DARPA GAILA program under Contract No. HR00111990058, the DARPA KAIROS program under PTE Federal Award No. FA8750-19-2-1004, NSF CRII Award #1850069, and an Amazon Research Gift. We thank NVidia for GPU donations. The webpage template was inspired by this project page.